Spark Streaming
构建在Spark上的实时计算框架,实现高吞吐量,容错机制的实时流数据处理。
数据流
内部数据流
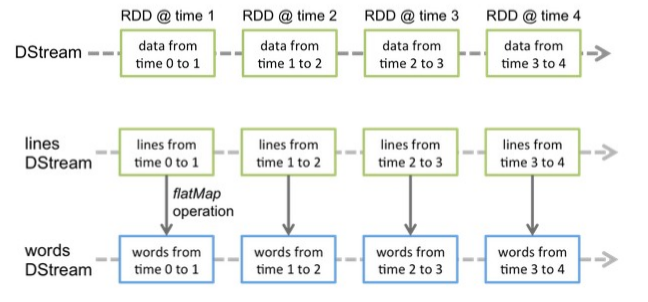
DStream
实时数据流,底层为RDD序列
DStream内部处理
Spark Streaming运行场景
三种运用场景
模拟一个流数据发生器1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47object Demo1 {
//得到长度内的随机数
def index(length:Int)={
import java.util.Random
val ran=new Random
ran.nextInt(length)
}
def main(args: Array[String]): Unit = {
if(args.length!=3){
System.err.println("<filename><port><mill>")
System.exit(1)
}
val filename=args(0)
val lines=Source.fromFile(filename).getLines().toList
val filerow=lines.length
val listener=new ServerSocket(args(1).toInt) //socket端口号
while(true){
val socket=listener.accept() //有人监听
new Thread(){
override def run={
println("from :"+socket.getInetAddress)
val out=new PrintWriter(socket.getOutputStream(),true)
while(true){
Thread.sleep(args(2).toLong)
val content=lines(index(filerow))
println(content)
out.write(content+"\n")
out.flush()
}
socket.close()
}
}.start()
}
}
}
1 | 运行配置e:\\TestStream\\a.txt 9990 1000 |
无状态操作
1 | val conf=new SparkConf().setMaster("local[2]").setAppName("streaming1") //local[2]开启俩个线程 |
UpdateStateByKey操作
updateStateByKey操作允许不断用新信息更新它的同时保持任意状态。你需要通过两步来使用它
定义状态-状态可以是任何的数据类型
定义状态更新函数-怎样利用更新前的状态和从输入流里面获取的新值更新状态1
2
3
4
5
6// 定义更新状态方法,参数values为当前批次单词频度,state为以往批次单词频度
val updateFunc = (values: Seq[Int], state: Option[Int]) => {
val currentCount = values.foldLeft(0)(_ + _)
val previousCount = state.getOrElse(0)
Some(currentCount + previousCount)
}
1 | val conf = new SparkConf().setAppName("StatefulWordCount").setMaster("local[2]") |
1 | sherlock 9990 30 10 |
window操作
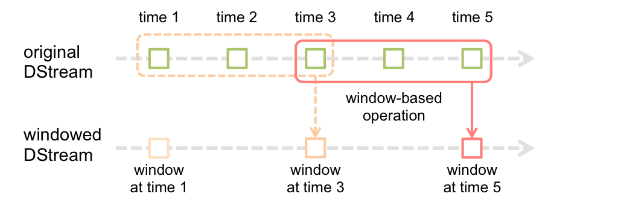
窗口长度:窗口的持续时间
滑动的时间间隔:窗口操作执行的时间间隔
这两个参数必须是源DStream的批时间间隔的倍数。1
2
3
4 // windows操作,第一种方式为叠加处理,第二种方式为增量处理 //windows的时间间隔大小(30s 则六个RDD为一个windows) windows窗口移动的时间间隔(10s移动一次,每切割俩次,移动一次) 必须为streamingtext的倍数
1.val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow((a:Int,b:Int) => (a + b), Seconds(args(2).toInt), Seconds(args(3).toInt))
2.val wordCounts = words.map(x => (x , 1)).reduceByKeyAndWindow(_+_, _-_,Seconds(args(2).toInt), Seconds(args(3).toInt))
1.win1=time0+time1+time2+time3 win2=time3+time4+time5
2.win2=win1+time4+time5-time1-time2
当滑动时间间隔远小于窗口长度是,前后俩个窗口时间片交集就越多,第二种方法对应得性能更高。
持久化和容错
持久化
– 允许用户调用 persist 来持久化
默认的持久化: MEMORY_ONLY_SER
对于来自网络的数据源 (Kafka, Flume, sockets 等 ) : MEMORY_AND_DISK_SER_2
– 对于 window 和 stateful 操作默认持久化
checkpoint
– 对于 window 和 stateful 操作必须 checkpoint
– 通过 StreamingContext 的 checkpoint 来指定目录
– 通过 DStream 的 checkpoint 指定间隔时间
– 间隔必须是 slide interval 的倍数