SparkSQL
在spark内核的基础上提供了对结构化数据的处理,允许用户直接通过hive表,Parquet文件以及一些其他数据源生成的DataFrame,提高JDBC读写表的能力,可以原生支持Postgres,Mysql等系统。
在Spark1.3中,引入了DataFrame来重命名SchemaRDD类型。
DataFrame功能特性:
1.多种数据格式和多种存储系统的支持
2.通过Spark SQL的Catalyst优化器进行先进的优化,生成代码
3.有KB到PB的数据集支持
SparkSQL的表数据在内存中存储不是采用原生态的JVM对象存储方式,而是采用内存列存储
该存储方式无论在空间占用量和读取吞吐率上都占有很大优势。
SparkSQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、Data Source(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result–>Data Source–>Operation的次序来描述的。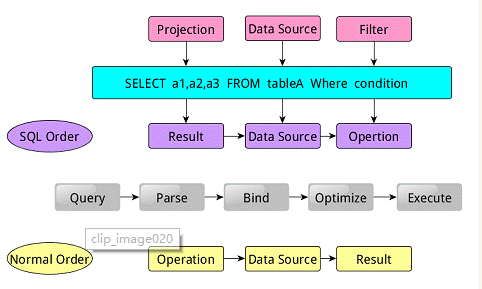
当执行SparkSQL语句的顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、Data Source等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation–>Data Source–>Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
数据操作
1.通用加载数据源方式1
2
3
4
5val df = sqlContext.read.load("examples/src/main/resources/users.parquet")
df.select("name", "favorite_color").write.save("namesAndFavColors.parquet")
val df = sqlContext.read.load("examples/src/main/resources/users.json")
df.select("name", "favorite_color").write.save("namesAndFavColors.json")
2.指定数据源方式1
2
3
4
5val df=sqlContext.load("XXX.parquet","parquet")
df.save("XXX.parquet","parquet")
val df=sqlContext.load("XXX.json","json")
df.save("XXX.json","json")
3.保存到持久化表中(存到系统上)1
df.saveAsTable("tableName")
4.保存到临时表中(应用退出销毁)1
df.registerTempTable("tableName")
读取文件
1 | case class Person(date:String,session:String,name:String,c_seq:Int,s_seq:Int,url:String) |
json文件
1 | val sc: SparkContext // An existing SparkContext. |
Parquet文件
1 | ... |
hive表
1 | sqlcontext.sql("HQL语句") |
This is an 官方文档