回归
回归是预测一个数值型数量,比如大小,收入和温度,而分类是指预测标号(label)或类别(category),比如邮件是否为垃圾邮件
分类和回归都需要从一组输入和输出中学习预测规则,属于监督学习
特征
类别型特征和数值型特征,类别型特征只能在几个离散值中取一个
回归问题的目标为数值型特征,分类问题的特征是类别型特征
12.5,12,0.1,晴朗,0 为特征 所有特征的集合为训练集
决策树
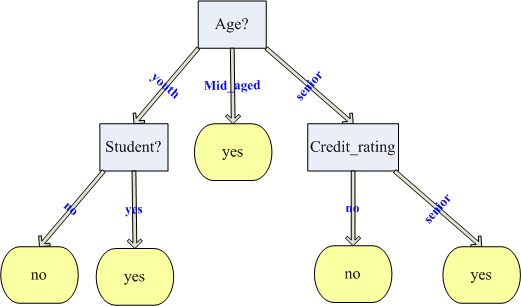
案例
准备数据
covtypedata 链接
分类变量如何编码,下面是编码的方式:
一个合适的编码方式是:one-hot 或者 1 of n 编码 一个分类变量:编码为 n(分类特征个数)个变量
另一种编码方式:就是给每个值一个固定的数字,例如: 1, 2, 3, …, n
当算法中把编码当作数字的时候只能使用第一种编码,第二种编码会得出滑稽的结果。具体原因是没有大小的东西被强制成有大小之分。
Covtype 数据集中有很多类型的特征,不过很幸运,它已经帮我们转换成 one-hot 形势,具体来说:
11到14列,其实表示的是 Wilderness_Area,Wilderness_Area 本身有 4 个类别
15到54列,其实表示的是 Soil_Type,Soil_Type 本身有 40个属性值
55列是表示目标值,当然它不需要表示成为 one-hot形式。
2952,107,11,42,7,5845,239,226,116,3509,1,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,1,0,0,0,0,0,0,0,0,0,0,0,2
使用数据
Spark MLlib将特征向量抽象为LabeledPoint 包括一个Vector和Label(目标值,从0开始)1
2
3
4
5
6
7
8val conf=new SparkConf().setMaster("local").setAppName("Decision")
val sc=new SparkContext(conf)
val rawData=sc.textFile("E:\\mllib\\CovType\\covtype.data\\covtype.data", 1)
val data=rawData.map { line =>
val values=line.split(",").map { _.toDouble }
val featureVector=Vectors.dense(values.init)
val label=values.last-1
LabeledPoint(label,featureVector) //特征向量
1 | 前5条记录 第一列为目标值-1 |
设定AUC指标
数据分为训练集,交叉检验集,测试集1
2
3
4
5
6//将数据分为完整的三部分 训练集80%,交叉检验集10%,测试集10%
val Array(trainData,cvData,testData)=data.randomSplit(Array(0.8,0.1,0.1))
//缓存数据
trainData.cache()
cvData.cache()
testData.cache()
构造模型
trainClassifier(数据,目标的取值个数,类别型特征信息,解释参数型,深度,桶数)
类别型特征信息Map[Int,Int] 元素的键为特征在输入Vector中的下标,值为类别型特征的不同取值的个数
例:map(10 ->4 , 11->40) 第10个特征有4个不同取值,11个特征有40个不同取值
深度是决策树的层数,桶为决策规则,桶数越多,决策规则越优。解释参数型为gini,Entropy1
2
3
4
5
6
7
8
9
10
11//在训练集上构造分类树模型
val model=DecisionTree.trainClassifier(trainData, 7, Map[Int,Int](), "gini", 4, 100)
//得到混淆矩阵和目标类型的取值有关
def getMetrics(model:DecisionTreeModel,data:RDD[LabeledPoint]):MulticlassMetrics={
val predictionAndLabels=data.map { example => (model.predict(example.features),example.label) }
new MulticlassMetrics(predictionAndLabels)
}
//用CVdata预测
val metrics=getMetrics(model,cvData) 7*7矩阵
准确率
精确度,召回率(被分类器标记为“正”的所有样本与所有样本就是“正”的样本的比率)1
(0 until 7).map(cat =>(metrics.precision(cat),metrics.recall(cat))).foreach(println)
多元的总体准确率
1 | //对准确度评估 |
参数选择1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17def evaluate(trainData: RDD[LabeledPoint], cvData: RDD[LabeledPoint]): Unit = {
val evaluations =
for (impurity <- Array("gini", "entropy");
depth <- Array(1, 20);
bins <- Array(10, 300))
yield {
val model = DecisionTree.trainClassifier(
trainData, 7, Map[Int,Int](), impurity, depth, bins)
val predictionsAndLabels = cvData.map(example =>
(model.predict(example.features), example.label)
)
val accuracy =
new MulticlassMetrics(predictionsAndLabels).precision
((impurity, depth, bins), accuracy)
}
evaluations.sortBy(_._2).reverse.foreach(println)
}
随机森林
由多个决策树独立构造而成
参数:数据集,目标的取值个数,类别型特征信息,决策树个数,评估特征策略,解释参数型,深度,桶数1
val forest=RandomForest.trainClassifier(trainData, 7, Map(10->4,11->40), 20, "auto", "entropy", 30, 300)
预测1
2
3
4
5
6//预测
val input="2709,125,28,67,23,3224,253,207,61,6094,0,29"
val vector=Vectors.dense(input.split(',').map( _.toDouble))
val forst_pre=forest.predict(vector)
val model_pre=model.predict(vector)
println(forst_pre+" "+model_pre)