Spark部署
前提是必须安装了hadoop
参考链接
下载资源
Spark下载
Scala下载
环境配置
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| export SCALA_HOME=/usr/local/scala-2.10.5
export PATH=$SCALA_HOME/bin:$PATH
export JAVA_HOME=/usr/local/java/jdk1.7.0_80
export PATH=/usr/local/java/jdk1.7.0_80/bin:${PATH}
export HADOOP_HOME=/usr/local/hadoop-2.6.2
export HIVE_HOME=/usr/local/hive-0.10.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$HIVE_HOME/bin:$SPARK_HOME/bin:$SPARK_HOME/sbin
export MAHOUT_HOME=/usr/local/mahout
export MAHOUT_CONF_DIR=$MAHOUT_HOME/conf
export PATH=$MAHOUT_HOME/conf:$MAHOUT_HOME/bin:$PATH
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export YARN_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export SPARK_HOME=/usr/local/spark-1.6.1-bin-hadoop2.6
|
source /etc/profie 配置生效
验证scala
配置spark
vim spark-env.sh
1
2
3
4
5
6
| export JAVA_HOME=/usr/local/java/jdk1.7.0_80
export SCALA_HOME=/usr/local/scala-2.10.5
export SPARK_MASTER_IP=master
export SPARK_WORKER_CORES=2
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
|
vim slaves
1
2
| 添加节点:
master 或者 127.0.1.1
|
启动spark
1
2
3
4
| cd /usr/local/spark-1.6.1-bin-hadoop2.6
启动:
./start-all.sh
|
jps查看进程
出现master worker
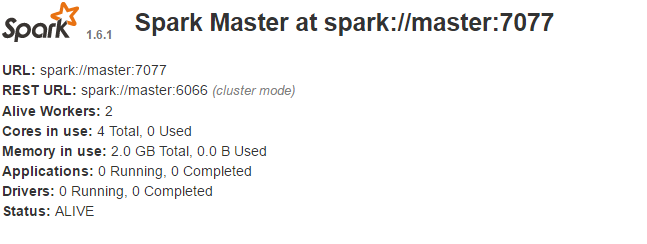
浏览器
http://master:8080